Author: Reshama Shaikh
Sprint Background
This “sprint” is a hands-on hackathon where participants learn to contribute to scikit-learn, a widely-used Python open source, machine learning library.
This sprint was organized by Data Umbrella to increase the participation of underrepresented persons in data science, with a focus on the geographic region of Latin America (LATAM).
This report focuses on the summary, impact and lessons learned of the Data Umbrella LATAM scikit-learn sprint.

Event Sponsor
This event was funded in part by a grant from Code for Science & Society, made possible by grant number GBMF8449 from the Gordon and Betty Moore Foundation.
Continued Contribution to Open Source
This sprint was a 4-hour block of time with pre- and post-sprint work required.
Participants were encouraged to keep contributing to scikit-learn or other Python libraries, using the skills learned in this event.
Sprint Agenda
- 19-Jun-2021: Pre-sprint Kickoff (11am - 1pm) (UTC-5)
- 26-Jun-2021: Sprint (11am to 3pm) (UTC-5)
- 10-Jul-2021: Sprint Follow-up Office Hours (11am to 12pm) (UTC-5)
Note: UTC-5 = São Paulo, Brazil Time
Sprint Day
The sprint officially ran 4 hours, which is limited time to submit a PR. The participants continued to work on their sprint PRs throughout the weekend.
Follow-up Office Hours
Office hours were set up 2 weeks after the sprint where some of the scikit-learn core contributors were available to answer questions on open PRs.
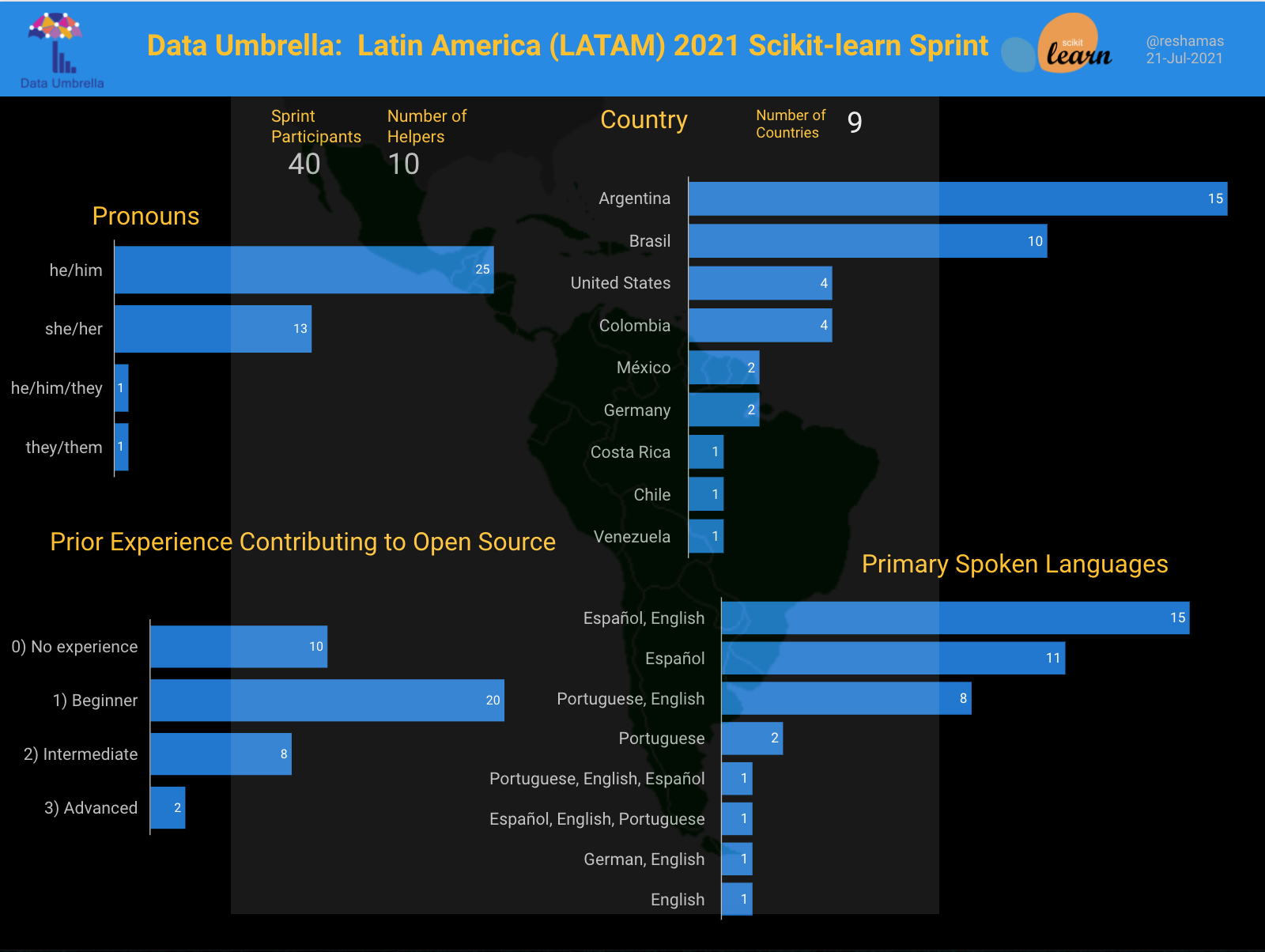
Demographics

A total of 40 contributors attended the sprint. 13 of 40 (32.5%) identified as she/her. 25 of 40 (62.5%) identified as he/him. 2 of 40 (5%) identified as “they”.
Contributors joined from 9 different countries. Country information was provided based on where participants were joining from. Argentina and Brasil had the most participants, for a total of 25 of 40, almost 63%.
Other Latin American countries represented include: Colombia, México, Costa Rica, Chile and Venezuela.
These other countries were also represented in terms of contributor background: United States and Germany.
There was one invited contributor who joined from Germany. Invited contributors were those who participated in a prior sprint and have continued contributing to scikit-learn.
There were two returning contributors, participants who had previously participated in a scikit-learn open source sprint. The invited and returning contributors were paired with a new contributor.
Applications Received
The countries in the Latin America region with the most applicants are:
- Brasil: 36
- Argentina: 26
- Colombia: 11
- Venezuela: 9
- México: 5
- Péru: 3
- Ecuador: 3
- Chile: 2
- Bolivia: 1
- Costa Rica: 1
- Guatemala: 1
Applications from regions outside of Latin America include:
- United States: 10
- India: 7
- Canada: 2
- Germany: 2
- Spain: 2
Other countries with one application each: Australia, Greece, Poland, Romania, Saudi Arabia, United Kingdom.
Spoken Languages
The sprint was in English with translators available to translate into Spanish and Portuguese. Languages spoken by participants included: Spanish, Portuguese, English, and German.
Open Source Background
75% of participants identified as having “none” or “beginner” level experience in contributing to open source.
Number of Participants
- Pre-sprint event: ~ 29
- Sprint: ~ 40
- Post-sprint event: 12
Impact Report for Data Umbrella Scikit-learn Sprint
| Sprint 2021 | ||
|---|---|---|
| Report date | 20-Jul-2021 | |
| Report author | Reshama Shaikh | |
| Sprint date | 26-Jun-2021 | |
| Location | Online; Latin America (LATAM) | |
| Sprint website | latam2021.dataumbrella.org | |
| Moment | ||
| Open source library | scikit-learn | |
| GitHub repository link | data-umbrella/data-umbrella-scikit-learn-sprint | |
| Lead Organizer | Reshama Shaikh | |
| Assistant Organizers | Mariam Haji, Cristina Mulas Lopez, Sara El-Ateif | |
| Lead Facilitator | Andreas Mueller | |
| Mentors / Translations | Melissa Weber Mendonça, Cristián Maureira-Fredes, Michael Eickenberg, Bruno Goncalves | |
| Scikit-learn core contributors | Thomas Fan, Adrin Jalali, Guillaume LeMaitre | |
| Teaching Assistants | None | |
| Platforms | Discord & Zoom | |
| Sponsor: | Grant GBMF8449 from Gordon and Betty Moore Foundation & Code for Science and Society | |
| PULL REQUESTS (PRs) | ||
| PRs [MRG] at sprint | 10 | |
| PRs [MRG] post-sprint | 50+ | |
| PRs open | 10+ | |
| Attendees: Initial Registrations | ~55 | |
| Attendees: Participated | ~40 | |
| Attendee List | Sprint Contributors | |
| Post-sprint Survey | [survey form] (closed) | |
| Blog 1: English | Data Umbrella Sprint - My Experience Sebastian Andres | |
| Blog 2: Spanish | Experiencias del Sprint de Data Umbrella Sebastian Andres |
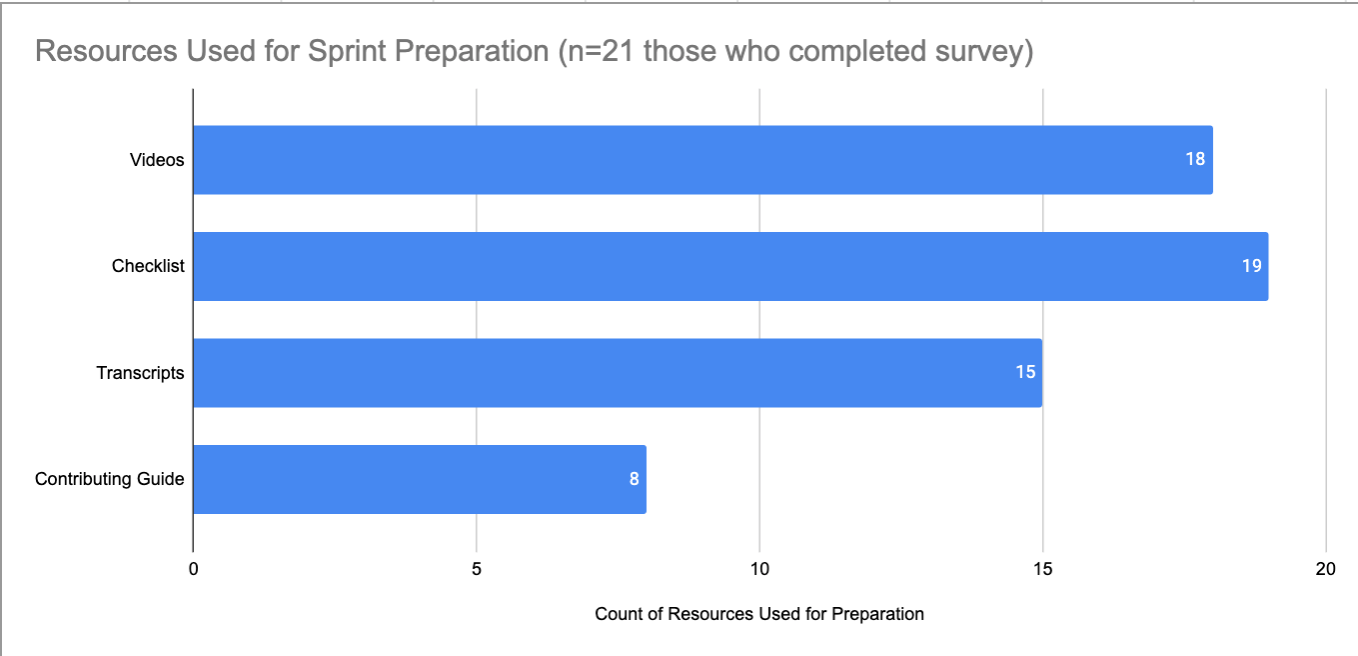
Resources for Contributing to scikit-learn
Because this was a virtual event and there is a limited capacity for being online for a full 8-hour day, a checklist was provided so folks could do preparation work at their own pace prior to the sprint. Resources for Prep Work are available on the sprint website.
A Checklist with highlighted notes to indicate updates from videos was also included.
This visualization shows which resources were used for sprint preparation. Note that n=21, which represents those participants who completed the feedback survey.
Impact
Non-measurable Impact
Aside from the number of PRs that were merged, there is non-quantifiable impact of the open source sprint. Some examples include:
- learning to set up virtual environment
- using Git (fork, clone, branch, fetching another’s PR)
- introduction to tests such as: flake8 (linting, formatting), pytest, “continuous integration”
- navigating through the codebase structure of scikit-learn
- digging into functions, learning about errors
- learning about unit tests
- interacting with contributors on GitHub
- learning, in general
- networking
- building confidence (making a dent in “imposter syndrome”)
- having fun
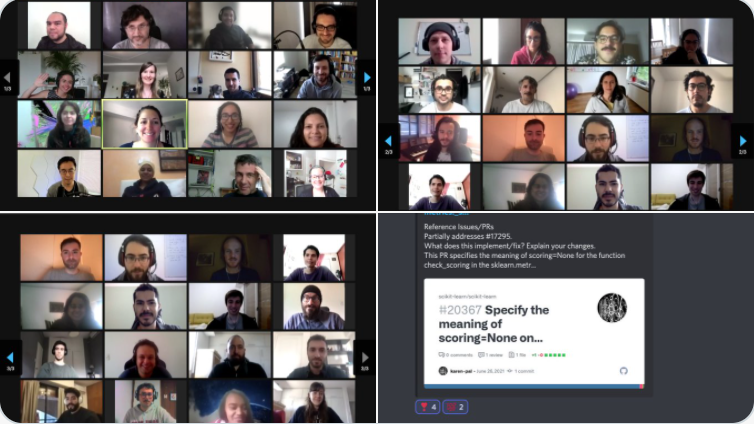
Event Outreach
Sprint outreach can be considered an impact. Even if folks do not attend or apply, the sprint outreach brings more visibility and interest to the project.
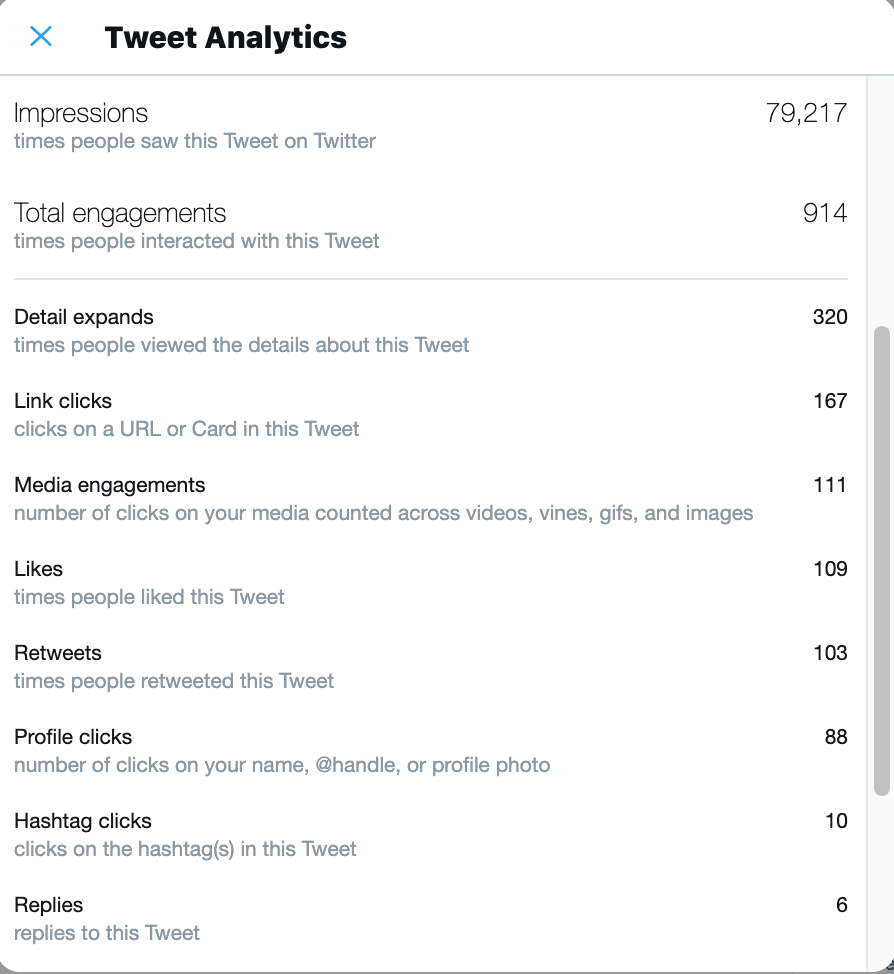
This LATAM sprint tweet had ~80K+ impressions and 160+ link clicks:
This LATAM LinkedIn post had 3200 impressions and 50 reshares:
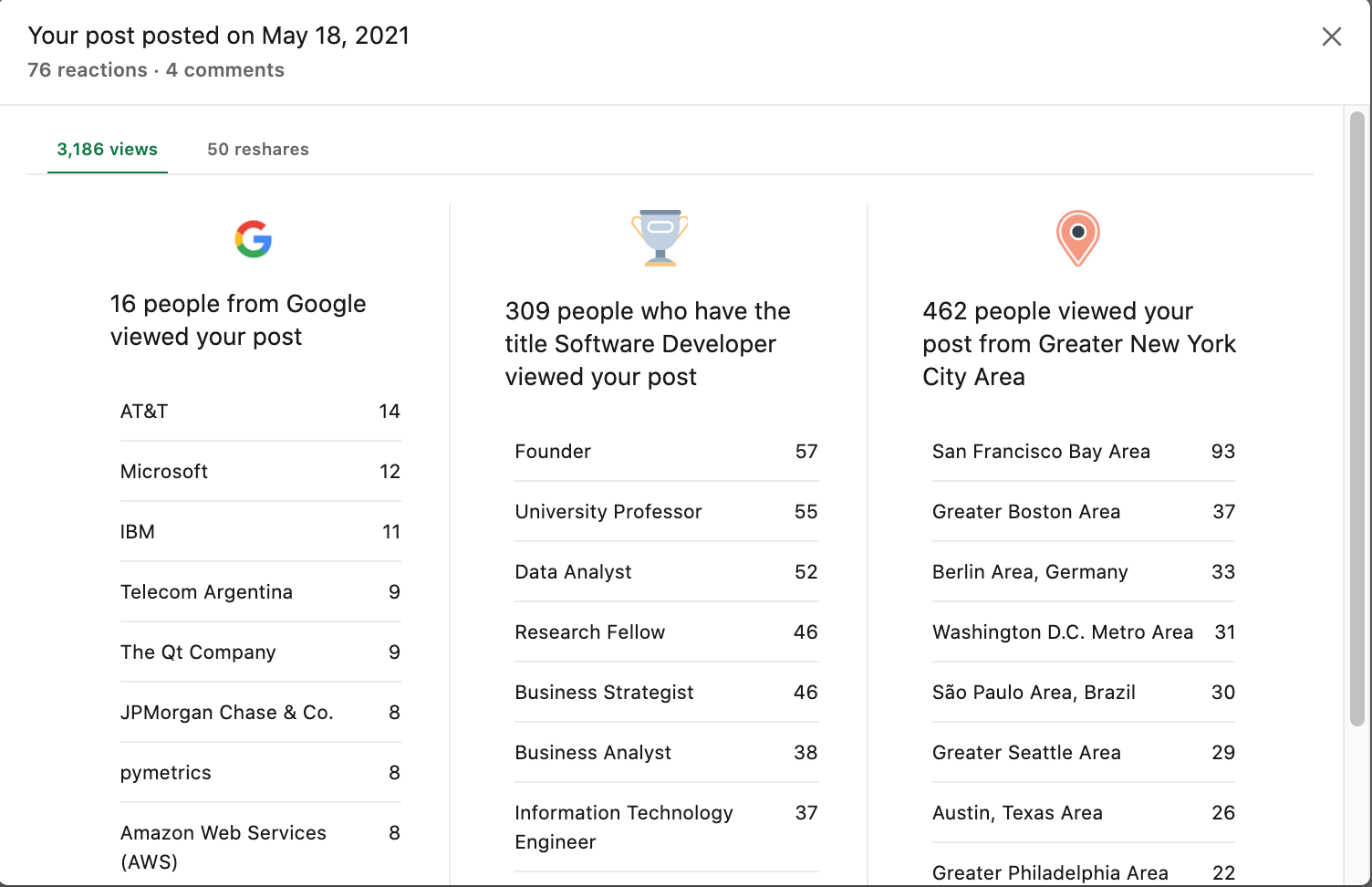
Google Analytics shows the reach of our marketing efforts:
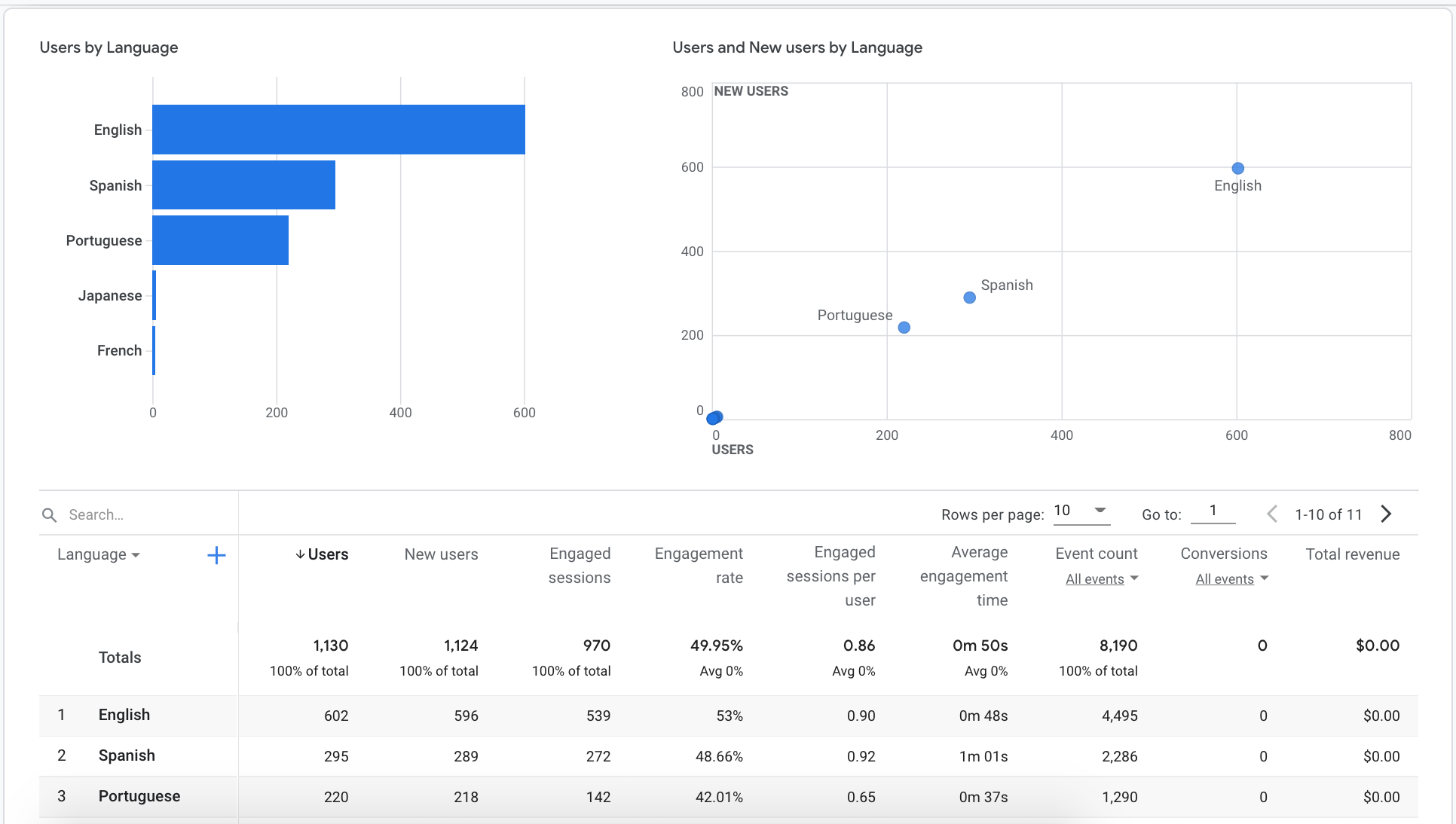
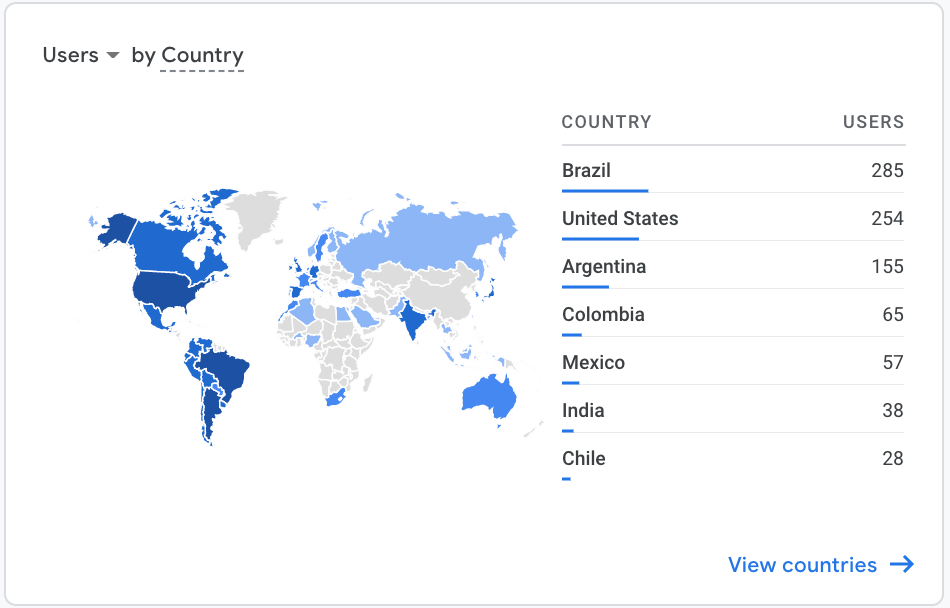
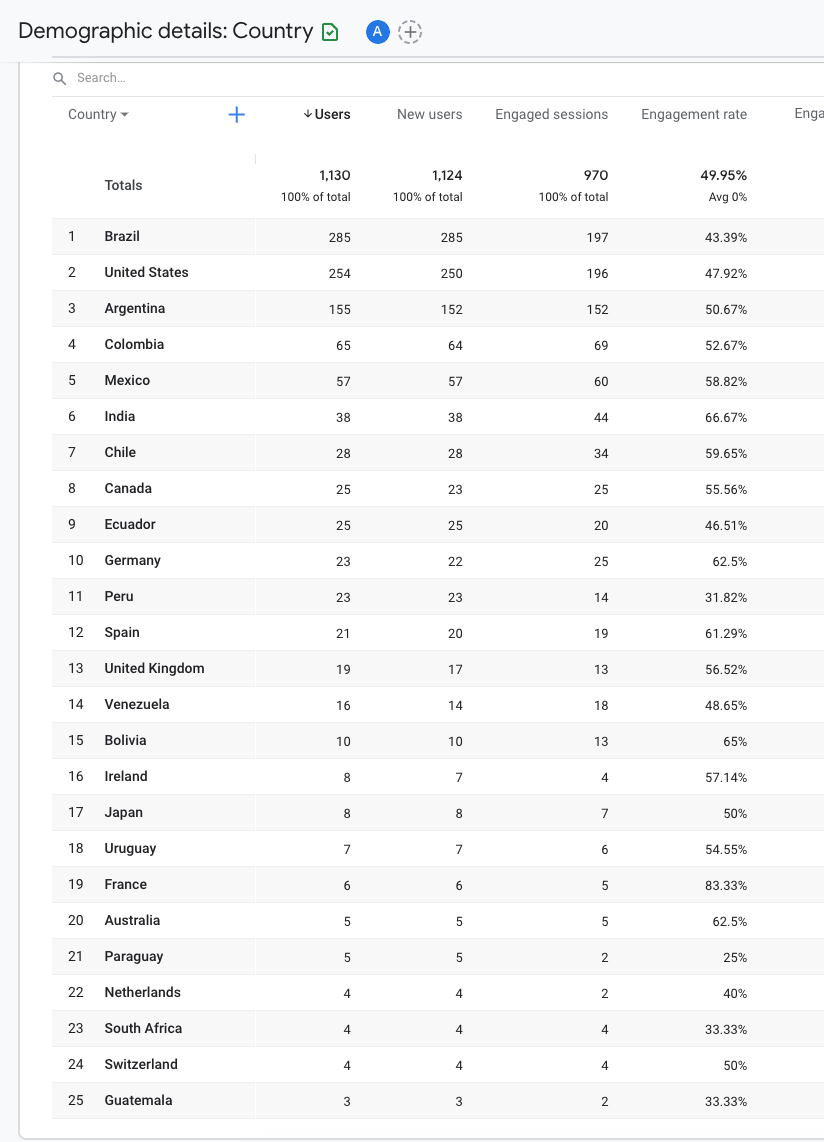
Challenges
Outreach
Outreach was resource intensive. The communities exist, and it takes intensive networking and meetings to find communities, the community leaders and the platforms to reach potential sprint participants.
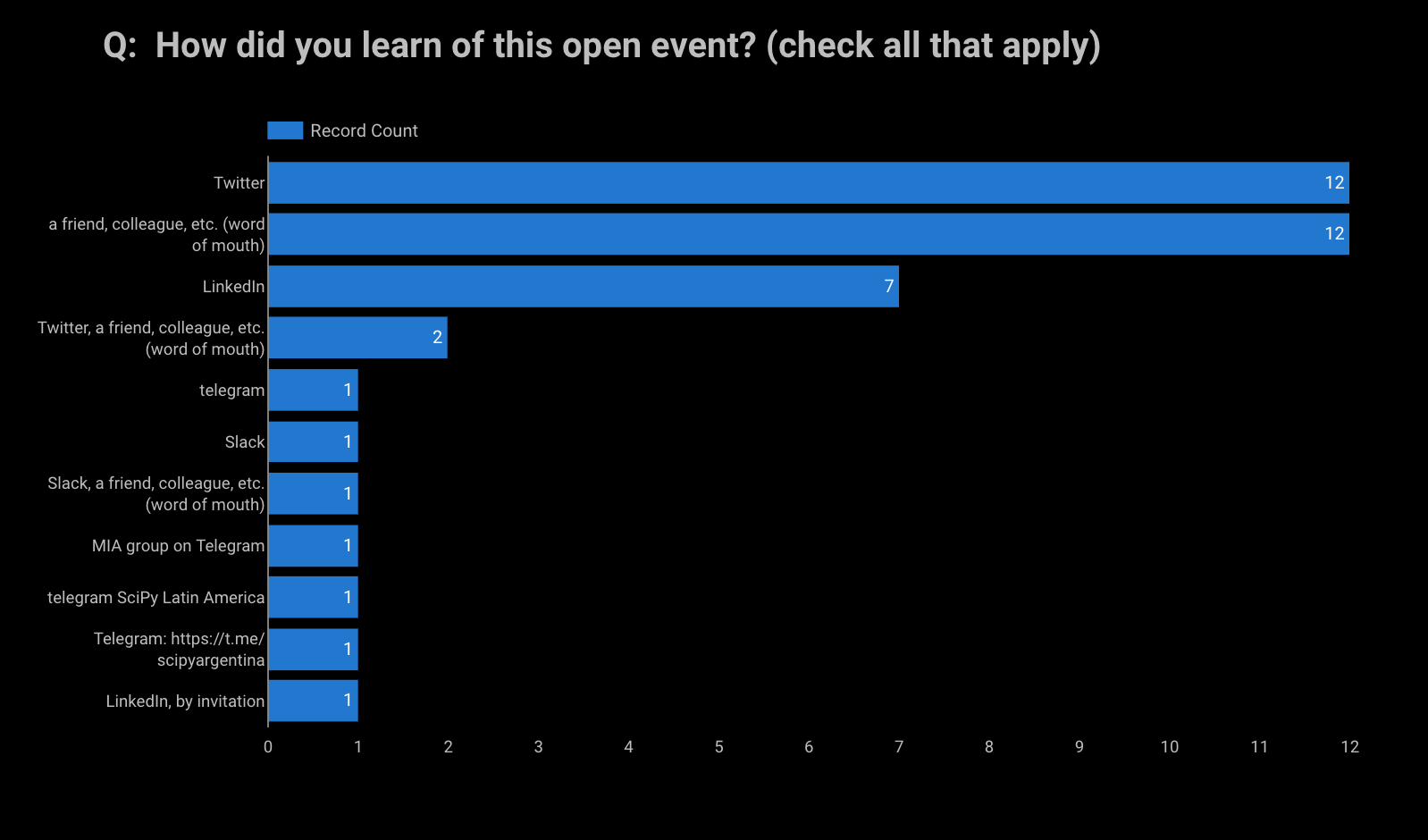
For those who attended the sprint, this is how they learned of the event. The main avenues were Twitter, LinkedIn and their network (“word of mouth”).
Videos
The videos that were created can be quickly outdated compared to static print. Videos are more accessible, but also take more effort to create.
Some of the video content created is outdated. A few of the following items need to be updated:
- branch on GitHub repo changed from
mastertomainin January 2021 - instructions for setting up virtual environment has been updated in the past year
Language Translations
Responses to the sprint outreach were initially low. The website and social media announcements were translated into Spanish and Portuguese. Also, a number of other resources were translated, including video transcripts and feedback surveys.
We had translators at all 3 events: pre-sprint, sprint, post-sprint.
It’s challenging and resource intensive to provide translations in 3 different languages.
Adjustments for Next Sprint
Collecting Names
Important to have an optional field for “Middle Name” in addition to “First Name” and “Last Name” in the application form for Latin America region.
Visual Studio Code
Explore live pair programming tools.
#DataUmbrella Hashtag
Reminder to sprint participants to include this hashtag #DataUmbrella on their pull requests so we can track them.
Videos
Videos are outdated. Consider if it is helpful to include them in the pre-work.
Sprint Feedback
Feedback has been shared a number of ways:
- Twitter Moment
- Blogs (* none yet* )
- Sprint survey
- Social media (LinkedIn)
- Casually, in conversation during the sprint, pre-sprint and post-sprint events
Data Umbrella Feedback Survey
Data Umbrella received 21 responses to our internal sprint survey. (21/40 = 52.5% response rate).
Respondents rated their overall sprint experience highly favorably and had a positive experience working with their pair programming partner.
Language
The survey was translated from English to both Spanish and Portuguese. This is the breakdown in responses received, by language:
- English: 16
- Spanish: 4
- Portuguese: 1
In response to the question “What are your favorite parts about the sprint?”
- Pull request (PR)
- The pre sprint was very helpful
- Everything! I was nervous but I could enjoy and learn all the event, was really good to meet everyone in Zoom and working with a partner.
- All, was ok!
- Working on the PR!
- I could work on two issues and meet some interesting people.
- Meeting new people and working in an open source project.
- The mentors that were ready to answer our questions, made me feel really secure about contributing
- Support from organizers and contributors. Engangement of the newbies. Overall networking.
- I liked the whole process, I can see the effort in the organization.
- Being able to be in touch with an open source project and realizing how I can contribute to it, even with limited coding skills.
- Discord time
- Nothing to comment about it, all was fine.
Some general feedback in the survey:
I think the difficulty of contributing to open source is two-fold:
(1) the tools: are not straightforward - `git`, `pytest`, etc.
(2) the knowledge: is very specific.
-
Maybe the preparation for the sprint could split the preparation into this steps. With github actions, learning the tools can be even easier.”
-
I loved that. It has been my first experience in contributing with open source.
-
Overall the sprint was a good experience, the one slight “issue” I had was with the prework. I stressed a bit trying to get it all done before the deadline, but that didn’t end up being important. It definitely was useful, though, I just happened to have a very busy week at work while preparing.
-
I was a bit shy to talk at the end of the event. I am really thankful to all the organizers. I am a great fan of sklearn so being able to participate was fantastic. Also, a great opportunity to learn in general and to learn how to contribute. Now I will continue contributing, but this was not something I thought I could do before, the Sprint and the mentors really help me to change my mind. The videos and documentation we had to read before the sprint were very useful.
-
It was a really nice experience. I felt supported by the mentors and my partner, the code was appropriate. It’s a great place to begin on contribute on open source.
Suggestions for Improvement
- A more step-by-step explanation for the “beginner PR” would have speed up things.
- If I had installed all required packages previously. I just installed the development and not the documentation ones.
- Maybe having two shorter separate sessions
- Issue selection and categorization.
- Probably the way to inform the time of the event, there were some misunderstandings with the time zones
- I didn’t have this problem, but I saw many people were waiting on an issue to be merged (that made them loose the momentum) and then they had a few merge conflicts. I think the attendees with the problem should have immeditaly banded together as a team with a few mentors that could guide them and explain them the process, because some confessed to me that they were scared of the merge conflicts and that more advanced git stuff.
- Instructions to test before submitting. For instance: to run
black, besidesflake8. - Having the videos updated
- It would be nice to have an article about free pair programming tools.
Social Media
Sprint: Social Media
The @DataUmbrella Latin America (LATAM) #ScikitLearnSprint has kicked off!#python #datascience #oss #machinelearning
— Reshama Shaikh (@reshamas) June 26, 2021
With a great turnout.
First PR (#20367) has been submitted! pic.twitter.com/opJdHtLXT7
Sofi
Yeey tengo commits en el repo de sklearn!! ❤️
— Sofi Denner (@sofide_) June 28, 2021
Acaban de mergear el PR que hicimos con @DrGleeks en el #ScikitLearnSprint 🙌🏼
Mil gracias @DataUmbrella por organizar el evento, estuvo muy bueno! pic.twitter.com/WM7hvnMkqE
Anavelyz
Alguien: Y... ¿qué es el open source?
— Anavelyz Perez (@AnavelyzJPR) June 27, 2021
Yo: Es la posibilidad de sumar y convertir pequeñas líneas de código en un proyecto fuerte que cambia constantemente para mejor...
¡Gracias @DataUmbrella y @scikit_learn por hacer posible nuestro primer Pull requests!#ScikitLearnSprint pic.twitter.com/mf8XDURzP5
Cristina
Second #ScikitLearnSprint done. Happy to be part of this family! #dataumbrella #opensource https://t.co/rePO07cSSK
— CristinaMulas (@MulasCristina) June 26, 2021
Jenn
Learning with @DataUmbrella and #ScikitLearn about #machine #learning #OpenSource was a great experience! https://t.co/98wdS2ykgN
— Jenn (@j3nnn1) June 26, 2021
Maren
So happy to be part of another scikit-learn sprint. I'm having a great time and am learning lots. 🙂👩🏼🎓 https://t.co/581dGmG7jk
— Maren Westermann (@MarenWestermann) June 26, 2021
Kardaver
yay! 🥳 my first PR merged to @scikit_learn , all thanks to #ScikitLearnSprint organized by @DataUmbrella
— kardaver (@kardaver2) June 26, 2021
Go team LATAM!!!#python #datascience #oss #machinelearning pic.twitter.com/HV9JrA5C6B
and a second PR merged! congrats for such a great event @DataUmbrella Everyone was really helpful and welcoming at #ScikitLearnSprint. I can totally see myself continuing to contribute to sklearn 🤩 love the community!#python #datascience #oss #machinelearning pic.twitter.com/xWpgReJT2T
— kardaver (@kardaver2) June 26, 2021
Andres
Learning how to #GivingBack to #opensource in #latam
— Andres Rios (@ariosramirez) June 26, 2021
whit @DataUmbrella and @scikit_learn
🤓🐍❤#python #datascience #oss #machinelearning https://t.co/FQFORF5zog
Sebastian
¡Llegó el día! Comienza el #ScikitLearnSprint de @DataUmbrella con foco en Latinoamérica.
— Sebastian Flores (@sebastiandres) June 26, 2021
My first PR submitted to @scikit_learn during #ScikitLearnSprint @DataUmbrella :https://t.co/jdsTRUmCgI
— Sebastian Flores (@sebastiandres) June 26, 2021
Pablo
First time at the @DataUmbrella LatAm #ScikitLearnSprint. https://t.co/S3hh8uH51B
— Pablo Ibieta (@pabloibieta) June 26, 2021
Mariela
Empezando el Latin America (LATAM) #ScikitLearnSprint !!!!
— )*.*( (@mariela_rajng) June 26, 2021
🤓🥳🤓#Python #MachineLearning https://t.co/ZWQgaNyYXm
Ludimila
Today is my first time contributing to open-source projects and starting contributing to sklearn makes me so happy cause it's a lib that changed everything in ML, thanks @DataUmbrella for the opportunity #ScikitLearnSprint
— Ludimila Carvalho (@ludigoncalves) June 26, 2021
JM
Last time I had some issues with my laptop during the The @DataUmbrella Latin America (LATAM) #ScikitLearnSprint, but today I'm on about to do my first PR to @scikit_learn 🤞but first I've to fix all the failing test :P pic.twitter.com/LE6kpJKqFu
— J. M. Nápoles (@napoles3D) July 10, 2021
Gloria
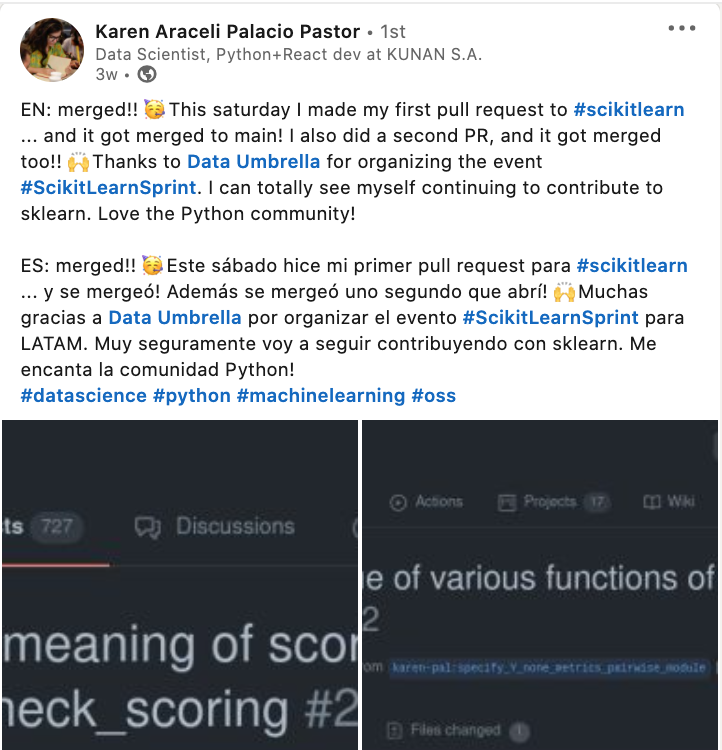
Karen
Social Media Promotion
Twitter (English)
🧵
— Data Umbrella (@DataUmbrella) May 18, 2021
📣Join us for our #ScikitLearnSprint
👉🏽with a focus on Latin America (LATAM)
🗓️26-Jun-2021
🕙11am-3pm UTC-5 (CDMX)
12-4pm EDT (NYC)
1-5pm UTC-3 (Sao Paolo)
🏢 Online
Thank you to our sponsors: @codeforsociety & @MooreFound
Details on application: https://t.co/XkO2ytLKcH pic.twitter.com/M1AWgXupPr
Twitter (Spanish)
🎉Únete a #ScikitLearnSprint
— Data Umbrella (@DataUmbrella) May 27, 2021
👉América Latina (LATAM)
📆26-Jun-2021
⏰11am-3pm UTC-5 (CDMX)
12-4pm EDT (NYC)
1-5pm UTC-3 (Sao Paolo)
🏢Online
Patrocinadores: @codeforsociety & @MooreFound
Aplicación: https://t.co/wLNX2uhugf
No te olvides de enviar la aplicación#Python pic.twitter.com/RoiPrUuXHP
Twitter (Portuguese)
pt_br (Brazilian Portuguese) 🇧🇷
— Data Umbrella (@DataUmbrella) June 2, 2021
📣Junte-se ao #ScikitLearnSprint
👉🏽América Latina (LATAM)
🗓️26-Jun-2021
• 11am-3pm UTC-5 (CDMX)
• 12-4pm EDT (NYC)
• 1-5pm UTC-3 (São Paulo)
Inscrição: https://t.co/wLNX2uhugf
Não esqueça de se inscrever pic.twitter.com/EP23Sqrnog
LinkedIn (English)
LinkedIn (Spanish)
LinkedIn (Portuguese)
Acknowledgments
- All the scikit-learn core contributors who mentored at the sprint and those who were online during the weekend afterwards to promptly review the submitted pull requests.
References
Upcoming Sprints
Past Sprints
- List of Past scikit-learn Sprints (scikit-learn wiki)
- List of scikit-learn Sprints (compiled by Reshama Shaikh)
- scikit-learn Sprints Organized by Reshama Shaikh
Addendum
- [no addendums or updates at the time of publication]


